We launched the first Pipedrive implementation package, Pipedrive Growth Accelerator, a few years ago. Since then, a lot has changed. We’ve rebuilt and reintroduced the package. In this entry, I want to reflect on what mattered to clients regarding Pipedrive back then, what matters to them now and why, and how our new Pipedrive implementation package, Pipedrive Booster 2.0, addresses these needs.
This article is an excerpt from the syllabus for our upcoming live online Pipedrive training, where we turn theory into practice and help you become a Pipedrive power user. In just half a day, our experts will condense hundreds of hours of Pipedrive implementations, audits, and best practices into a hands-on workshop. Secure your spot today!
See you at the workshop!
Original Pipedrive implementation scope
The original Pipedrive package, Pipedrive Growth Accelerator, focused on automating manual processes with Pipedrive’s workflow automation suite. This included syncing inboxes, matching emails to contacts, implementing LeadBooster chatbots, eliminating administrative tasks and reducing manual data entry.
We enriched and validated data using Pipedrive’s Smart Data, providing growth teams with better lead context. Our custom scoring engine, the only custom-coded element, judged lead quality and helped allocate deals. Reporting was managed with Pipedrive’s Insights module. No custom analytics or data systems were used.
A notable implementation of this package was for a financial company, detailed in our Pipedrive implementation case study.
How needs towards Pipedrive have changed
I was seeing how the landscape and expectations are changing over time. Here’s a survey of the key shifts that have made us rebuild our approach to Pipedrive implementation.
Pipedrive and its data have stopped being the ultimate source of truth but are now part of a larger tech stack with which Pipedrive needs to communicate in real-time. This leaves operational workflow automation using built-in and default Pipedrive data seen as basic. The clients’ focus has shifted from eliminating manual tasks to automating processes running in Pipedrive not just based on what happens in Pipedrive, but also on what happens in other parts of their businesses. Moving deals across stages on autopilot based on the sentiment or outcome of a chat in a third-party tool, or initiating contract signing based on the sentiment of sales calls automatically, is what we’re implementing at the moment. Another typical need is for the key Pipedrive interactions feeding custom notification systems (more advanced than the default ones found in the Pipedrive workflow automation).
If the only shift were that companies want their Pipedrive to communicate and act based on what’s happening in other tools, we would be done quickly. Now they want the external data feeds to flow freely and generate derivative data points and metrics inside Pipedrive, which raises the challenge to a new level. Challenge accepted, though, as we believe that extended analytics are really needed to get a full picture of what’s changing in your business, particularly in such a dynamic endeavor, as I’ve pointed out in one of the latest Instagram reels.
Deal value, probability of winning a deal, and other critical data points that feed everything else in Pipedrive—from Insights reports to email campaigns to Sales Assistant—are now typically expected to be derived automatically using data points coming from multiple data sources in real time. A good example is the final deal value in Pipedrive, calculated based on company size sourced from external sourced like Clearbit, run through currency conversion, and possibly discounted by some sort of LTV metric generated from the long-term client database. Third-party data enhancements, and plugging aggregate information to various alerting systems is happening too these days.

Datapoints from other channels are expected to enrich the details and materials used for closing sales and nurturing too, and not just automate processes. Third-party data, such as web conversion or activity data, is now integrated into sales templates, contracts, and materials. For example, it’s common with our clients to automatically enrich company data with external points like NAICS codes and legal names, then incorporate these into contracts using Pipedrive’s automation suite. These external data points are written into Pipedrive’s internal data schema via custom fields. Additionally, behavioural scores derived from activities across multiple channels (web, mobile, CRM) are often added to lead/deal data to determine Pipedrive lead labels or deal stages. I also see an urge to optimise deal distribution based on more intricate logic than just the source of a deal. Thus, it’s not just critical Pipedrive values and metrics that are impacted; it’s the wealth of external data enriching the inside of Pipedrive itself.
Clients want reports that combine Pipedrive data with third-party data. Pipedrive still has one of the strongest BI platforms among CRM systems, and companies find it highly valuable. However, there’s a growing trend towards completely custom data models, allowing full control over how specific metrics are generated. This pressure pushes raw data out of Pipedrive, via ETL processes, into data warehouses, and from there into custom-build metrics models connected to the BI layer. This helps businesses understand their sales in a broader context. Reports also must be real-time, and we generally see the demand for batch and historical reports diminishing. Pipedrive metrics are being plugged to real-time notification and alerting/monitoring systems, enabling businesses to stay on top of their growth trajectories and trends and act when necessary.
Traditional tools that automate individual tasks between platforms are being quite brutally reconsidered. Managing data from multiple sources requires careful handling—cleaning it up, using filters to find useful insights, and integrating. These tools weren’t designed for that. For instance, updating Pipedrive with current currency exchange rates can involve 5-6 steps for each deal update. This quickly increases the total ownership costs of these tools when applied to many deals. It also makes the task sequences built in task automation platforms horribly unmanageable. What matters most is ensuring smooth data flows and pipelines that generate valuable information efficiently and integrate them into specific Pipedrive deals and leads to build context. Hence, there’s a growing preference for tools that process pipelines rather than focusing solely on individual tasks.
I see companies embrace privacy, security visibility, and permissions levels more bravely compared to a few years ago when these weren’t major concerns. Now, our setups must have clear rules on who can see what and do what, tailored to everyone’s job roles. Regulations like GDPR have shaped how we use Pipedrive—every deal must have GDPR consent marked before we can send any campaigns. Pipedrive handles this well from the product end, but the rules keep evolving.
Everyone asks for implementing AI/ML capabilities inside Pipedrive, but I think most companies aren’t ready for AI due to poor data quality in their Pipedrive setups. CRM platforms often struggle with issues like duplicate data and outdated information. Enhancing data quality in CRM systems is essential for successful AI implementation in the future. Companies wanting to boost their Pipedrives with AI further should start by improving data quality before diving into AI, which could take several months to get right. Our partner company, Samurai Technology, has outlined steps to follow to get a Pipedrive account ready for an AI integration.
Challenge accepted: running Pipedrive on Omni CDI
All the above turned into a pretty obvious conclusion: we want real-time event pipelines with custom transformations enrich Pipedrive accounts and provide more datapoints to the growth and sales teams to act upon. That’s how Pipedrive Booster 2.0 was born. We’ve rebuilt our Pipedrive implementation package to align with where the world is at now and where it’s going.
In our new package, we put significant effort into the initial stages of Pipedrive implementation to ensure a well-thought-out data model and robust security controls. The Pipedrive data schema must be carefully planned because changes to it can leave you unable to use analytics accurately for automated deal valuation and custom reports. We ensure that everyone in your account sees and does what they’re allowed to by maximizing the use of Pipedrive’s extensive visibility groups and permission levels.
The new implementation scope includes the automation of deal valuation and assignment using completely custom formulas and logic, leveraging any number of custom fields. It integrates data from third-party systems, such as data enrichments and validator processes, into sales templates, contracts, and email templates. This helps you to act immediately and automate processes based on what’s happening elsewhere in your business, using specific external data points inside Pipedrive, such as in email marketing campaigns, contract generation, or sales emails.
High-quality data in Pipedrive now writes to a warehouse in real-time. This enables us to perform real-time reporting using a variety of completely custom metrics and data points. Pipedrive deal closings and conversions trigger conversions in ad platforms, allowing you to run advertising at the bottom of the funnel by creating advertising audiences and offline conversions from Pipedrive activities. This helps you automate marketing, advertising, ad budget distribution, and bidding.
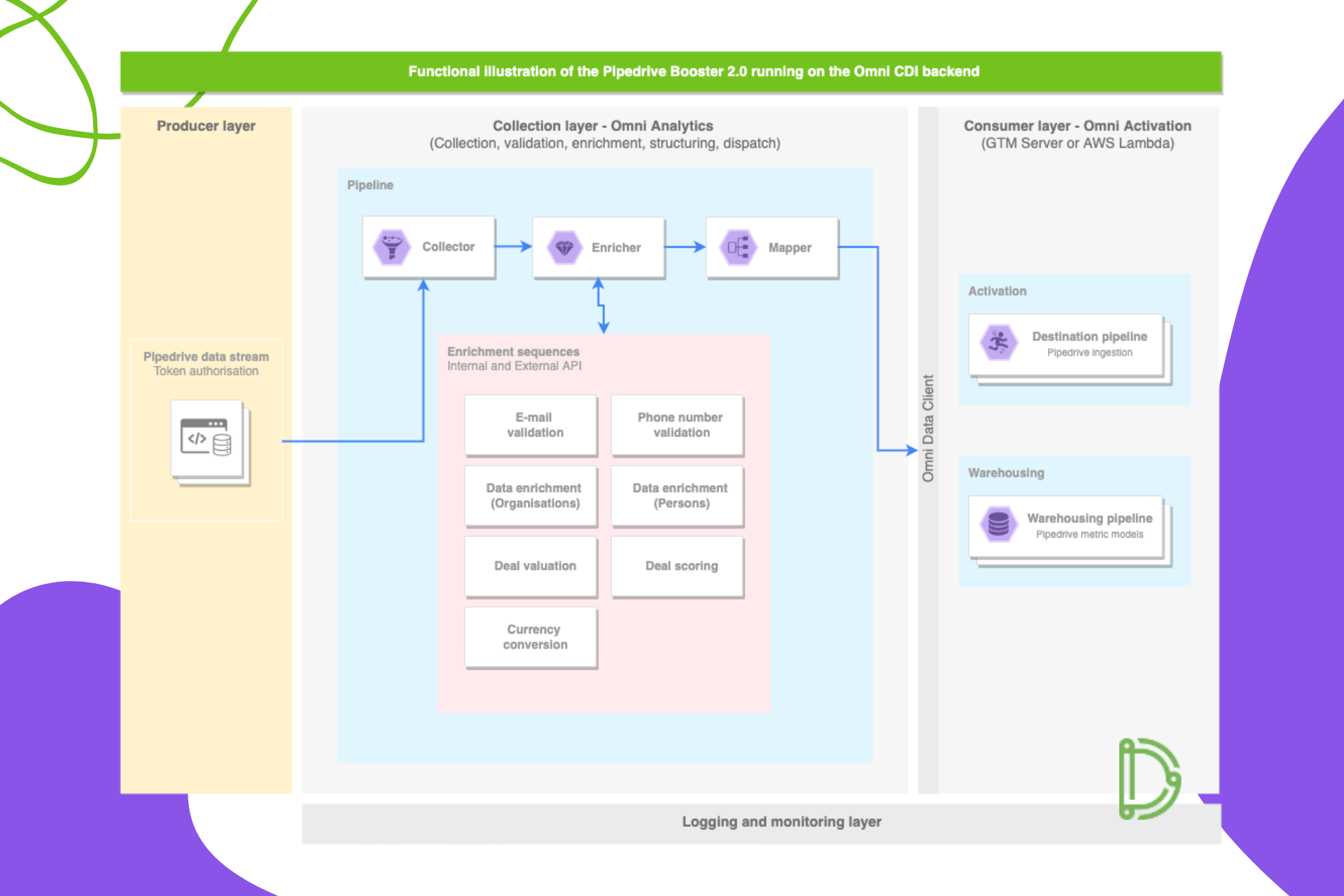
Let’s take a look behind the curtains and see how it’s all possible, actually. Below is the functional representation of the analytical backend on which Pipedrive Booster 2.0 runs.

Pipedrive Booster 2.0 runs on Omni CDI analytical backend, our own platform for real-time analytics, and it doesn’t rely on any third-party tools like well-known task integrators or external customer data platforms. Omni CDI is designed to handle high-volume event data pipelines cheap. It has multiple components, including data collectors, enrichers, an activation layer, reporting, and many others, ensuring that it’s possible to combine multiple data pipelines and make them all provide super valuable datapoints for the growth and sales teams to use to sell faster. Omni CDI allows us and our clients complete control over the value we extract from the data.
Pipedrive Booster 2.0 uses single pipeline implemented in Omni Analytics that handles collection, enrichment, and structuring. It processes 25+ HTTP callbacks from Pipedrive covering deal and lead management, contacts, organisations, and campaigns. These callbacks, validated against a schema, include approximately 90 data points and are fed into further enrichment processes, which add even more data from Pipedrive API and third parties. The final payload, which includes over 100 points, is then routed through the activation layer for reporting, ingestion, and custom dashboard creation, giving clients full control over their data.
A good practical example of all this in action is the latest case study of the Pipedrive Booster 2.0 implementation for Vyde.
What’s next
The state of needs and sentiments we’ve described, and our response to them, will remain relevant for probably another year or so. After that, the sentiment will shift again, focusing more on AI integration and using reporting metrics to actually automate sales, not just dashboards.
Currently, as we look forward to the future, it’s crucial for anyone developing CRM systems or aiming to future-proof their systems to invest in a robust data schema, operational automations to maintain data cleanliness, and treat their accounts as integral components of larger data streams. This involves taking raw data, enhancing it through various activities, and outputting enriched data, possibly to a central warehousing pipeline, ensuring complete ownership of their data. Additionally, a significant trend we’re observing is companies increasingly prioritising full control over their data. This means even if they unsubscribe from a specific tool, they retain access to all accumulated knowledge and data over the years.
